Remember one of the steps in computing eigenvalues
This was the step where is transformed to an upper Hessenberg matrix to reduce the computational cost of the QR iteration algorithm.
Let’s rewrite the equality as
where is upper Hessenberg.
Upon inspection, once is chosen, the other vectors in are fixed:
This algorithm is very similar to the Gram-Schmidt algorithm for the QR factorization but it uses .
We get column of
Let’s remove the components of in span(, …, ):
is the norm of the right-hand-side vector; once we have , we get:
Iteration
Start from . Then:
- Compute . This requires a sparse matrix-vector product.
- , .
- If you continue this iterative process to the end, you get a dense matrix .
- The sparsity advantage is lost.
- But what happens if we stop before the end?
- By using the top left block of we will be able to approximately compute eigenvalues and solve linear systems. As long as remains small, this can be computationally very fast.
Details of the iterative process
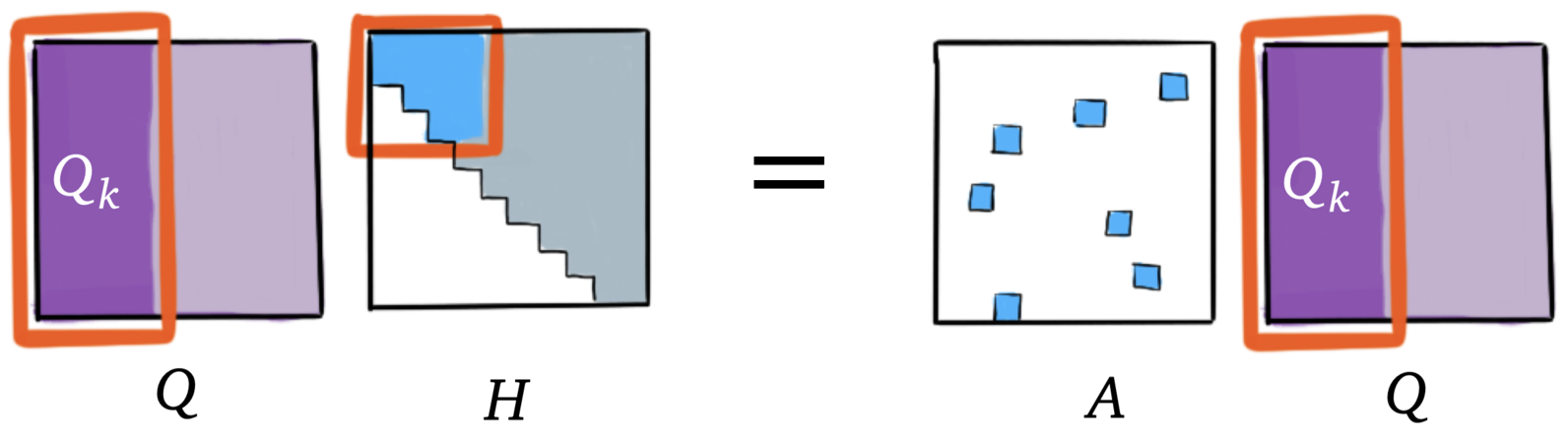
If we stop at step , we get the following equation:
and
if is small. This suggests using the following matrix
instead of .
From that point, iterative algorithms replace a calculation using with a calculation using . is a small matrix, and “direct” methods are efficient and fast.
The main application cases are the conjugate gradients method (which we will cover later) and the Arnoldi process.